Say we have to find an isomorphism between two graphs, Graph A and B.
To represent the graphs, we use the data structures created in the Gclient package, such as adjacency matrices.
Additionally, we use the following data structures in our program
We construct a matrix M that captures the mapping from A into B as follows
| M(i,j) | = 1 if a_i can be mapped to b_j |
| = 0 otherwise. |
So initially all the entries of the matrix M are 1, because any vertex of A can be mapped to any vertex of B. Using our algorithm, we desire to reduce the matrix M to a permutation of the identity matrix. Such a matrix would capture the graph isomorphism.
for example: if deg a_i != deg b_j, then we can easily set M(i,j) = 0; i.e., we cannot map a_i to b_j.
For each graph, say A, we make the shortest distance matrix, say D_a, for which every element D_a(i,j) is defined as:
D_a(i,j) = shortest distance from node a_i to a_j
Similarly for B,
D_b(i,j) = shortest distance from node b_i to b_j
The distance matrices are used to determine the repercussions when node a_i is node a_i is mapped to b_j.
During the program, we need to try certain possible mappings. For example, say we assume that a_i is mapped to b_j. Since we do not know if this will lead to a proper mapping, we have to maintain this assumed mapping in a stack. Further, after this mapping is made, the distance matrices are used to further assign some more vertices of A to B. These repurcussions are also stored in a Stack. If we encounter a situation, where any vertex of A cannot be mapped to any other vertex of B, then we infer that the assumptions made were wrong. Hence we pop the Stack.
Thus the Stack contains all the changes (assumptions + repurcussions) made to the Matrix M during the algorithm.
As we mentioned before, the aim of the algorithm is to reduce the Matrix M to a permutation of the identity matrix (if isomorphism exists). Hence, all through the algorithm, we aim to reduce the non-zero entries of Matrix M to zero, so that the properties of the graphs such as interconnections are still consistent.
To do this we use a Chess-like approach:
At any stage in the algorithm, we have a Matrix M that has been reduced by previous operations. If the Matrix is not fully reduced, then we have to make the next "move", i.e., we have to assign one more node of A to some specific node of B. We then evaluate the immediate repercussions of the "move" by using the distance matrices. If the "move" results in an inconsistency, then we undo this "move" and make some other "move", until we have no more valid "moves". If the immediate repercussions still result in a consistent mapping, then we go ahead and make the next move and evaluate its implications.
Thus the various data structures described above have the following roles
M : Stores the progess of the mapping at a given stage
Stack: Stores the the changes made to M during the "moves" and their repercussions.
Distance matrices: Helps evaluate the immediate consequences of making any "move".
Step 1: Fast rejection
In this step, we determine if a isomorphism is possible at all by ensuring that the number of nodes and edges and both the given graphs match. We also check if the sorted vector of degrees of each nodes match with each other.
Step 2: Preprocessing
In this step, we preprocess the matrix and reduce as many entries of M to zero as possible by allowing only vertices with the same degree to be mapped to each other.
At the end of this step We do another fast rejection. we check to see if still isomorphism is possible, i.e. there is at least one nonzero element in every row (and consequently in every column) of matrix M
Step 3: Calculating the shortest all-pair distance matrix for both graphs.
We use the Floyd-Warshall's algorithm to find the shortest distance between two vertices in the graphs A and B. We denote these matrices as distance filters D_a and D_b respectively. These matrices will be used to prune the search possiblities.
Step 4: Distance filtering
The distance matrices can concisely capture the inter-connectivity of the respective graphs. Distance filtering exploits the distance matrices D_a and D_b to ensures that only vertices with equal distances from already assigned nodes can be mapped into each other [1]. Thus, it helps us prudently eliminate possible mappings early as follows. For example, assume a_i is assigned to b_j after the preprocessing step. Then,
| M(k,p) | = 1 if D_a(k,i) == D_b(p,j), |
| = 0 otherwise. |
In words this means that a_k can be mapped to b_p only if their respective distances from assigned nodes a_i and b_j are equal. We recursively apply distance filtering to all assigned nodes in Step 1, till no more nodes are can be precisely assigned to each other.
This step yields us a very sparse matrix; in otherwords, this reduces the number of permutations we need to check in the graph.
Step 5: Efficient search algorithm
(i) If all vertices have been assigned if Valid isomorphism Print permutation, quit else Print Unsuccessful, quit end else (ii) Pick a vertex V_a with at least two nonzero elements in the corresponding row of Matrix M. For each nonzero entry V_b in that row of M, do the following: (iii) Assumption: assign V_a to V_b. Save this assumption on the globally-defined Stack data structure. (iv) Repercussion: Use the distance filters to set as many possible entries in M to zero as possible. Save all of those repercussions on the globally-defined Stack data structure. (v) Check if any inconsistencies occur, i.e.,if any vertex has no possible mappings. If inconsistencies occur Undo the latest assumption and repercussions by popping them off the Stack. Go to Step 5 (ii), and assign the next V_b to V_a. else Go to Step 5 (i) (make next assumption) end (vi) Report no isomorphism exists (since all possible pairings in Step 5 (ii) have been exhausted).
The algorithm requires O(N^2) memory. In fact the sizes of the dominant data-structures used in the algorithm are:
| DS name | Size | Type | Memory required |
| Matrix M | NxN | byte | N^2 |
| Adjacency matrix A | NxN | byte | N^2 |
| Adjacency matrix B | NxN | byte | N^2 |
| Distance matrix D_a | NxN | int | 4xN^2 |
| Distance matrix D_b | NxN | int | 4xN^2 |
| Stack | NxNx3 (max) | int | 12xN^2 |
Total = 23xN^2 bytes.
(Note: We have ignored all the N-sized data structures in the calculation above.)
The number of operations required for different steps in the algorithm is as follows:
To compile and use our solver for yourself, download this file and follow the instructions in the README file.
Solutions to all of the benchmarks that we have solved are available here.
Since we did not use a randomized algorithm, results are always accurate, although the program may run for any length of time.
When we first ran the solver on the benchmarks, we neglected to record the CPU time required, or the actual number of edges in the graphs. However, we subsequently reran all of the benchmarks with 1000 or fewer vertices in order to obtain timing information. Here, then, are charts of the CPU time spent on selected groups of benchmarks.
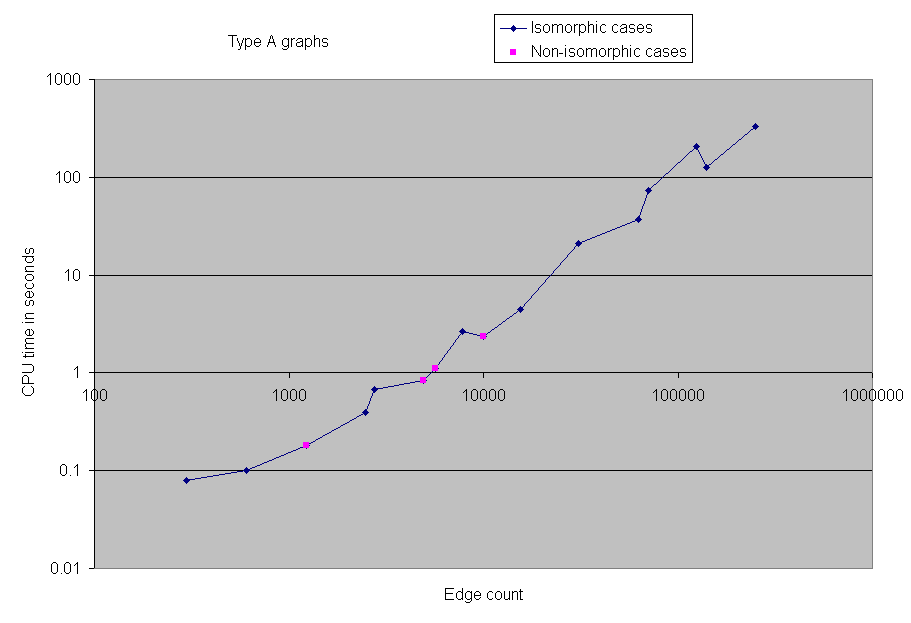
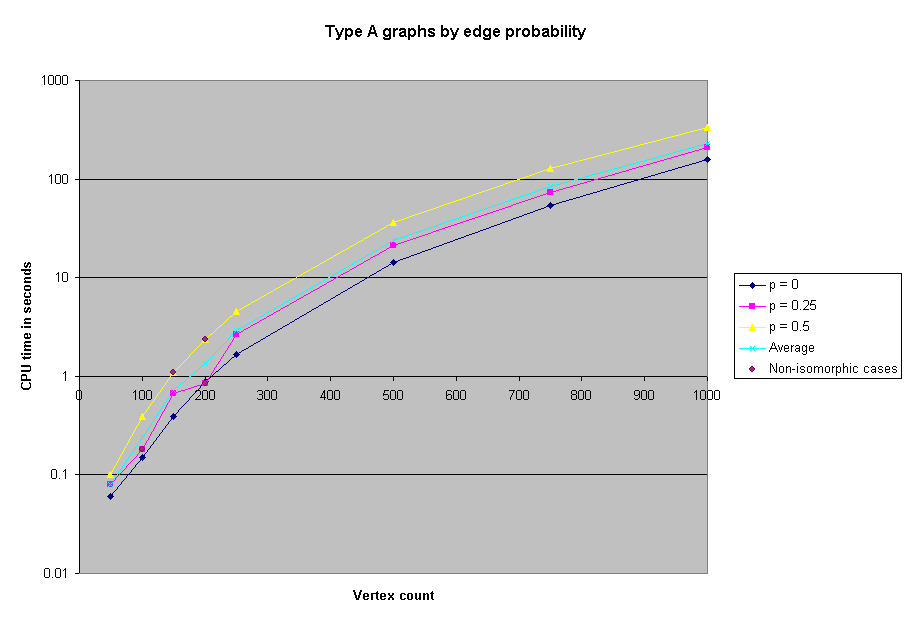
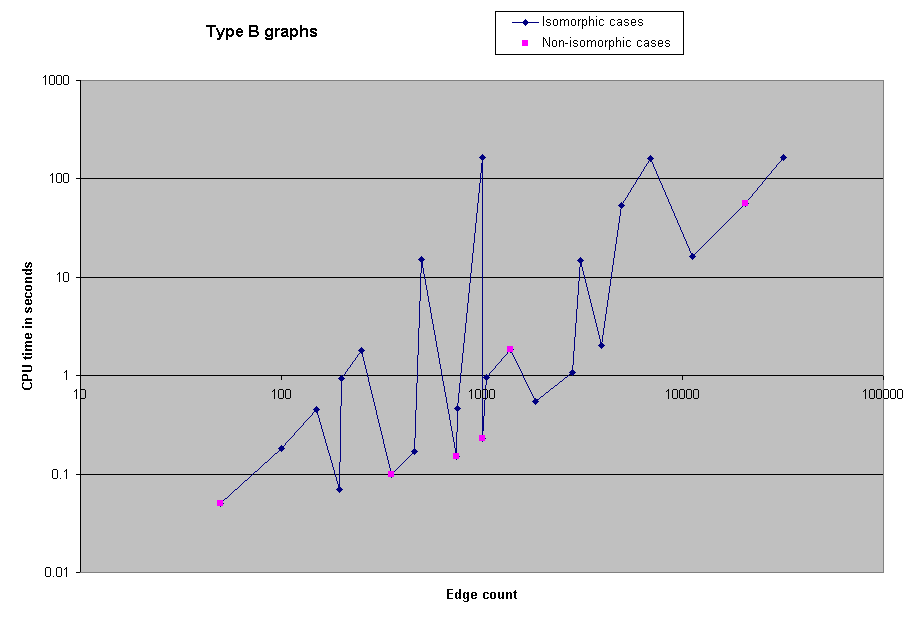
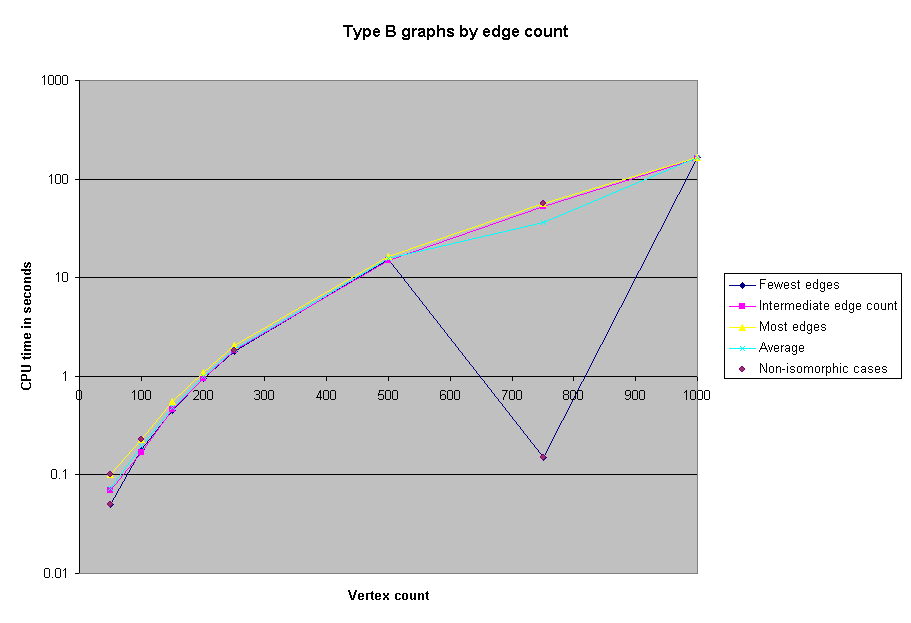
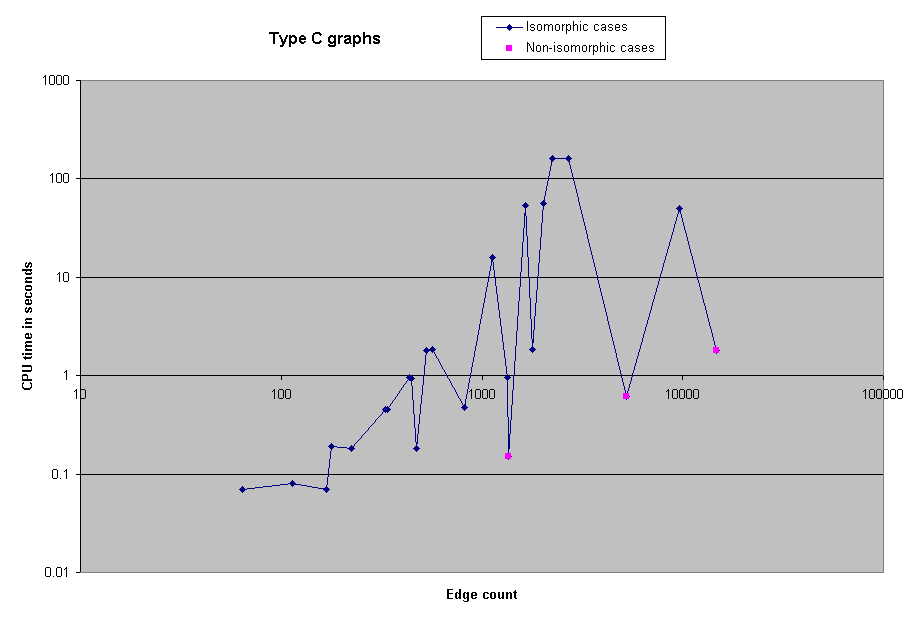
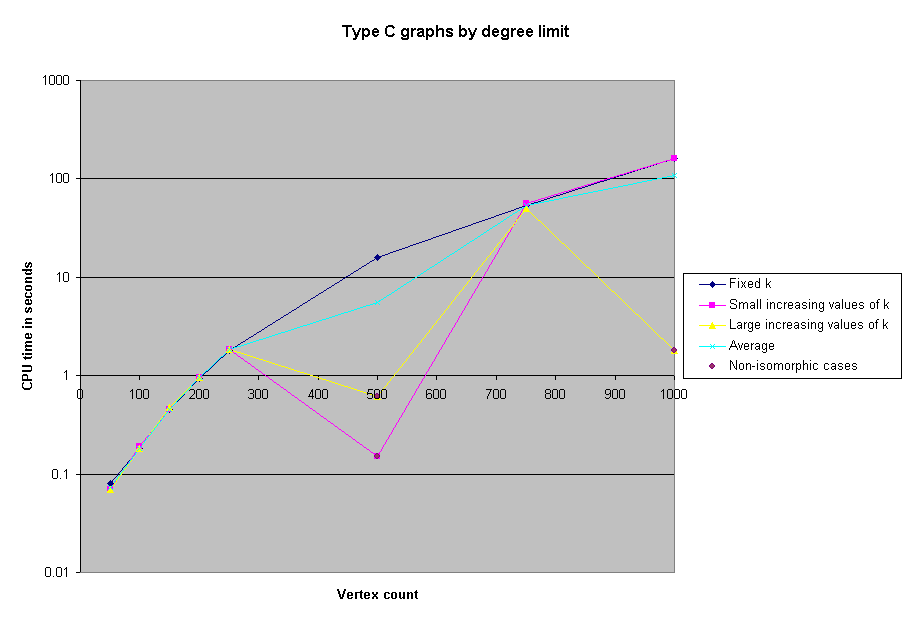
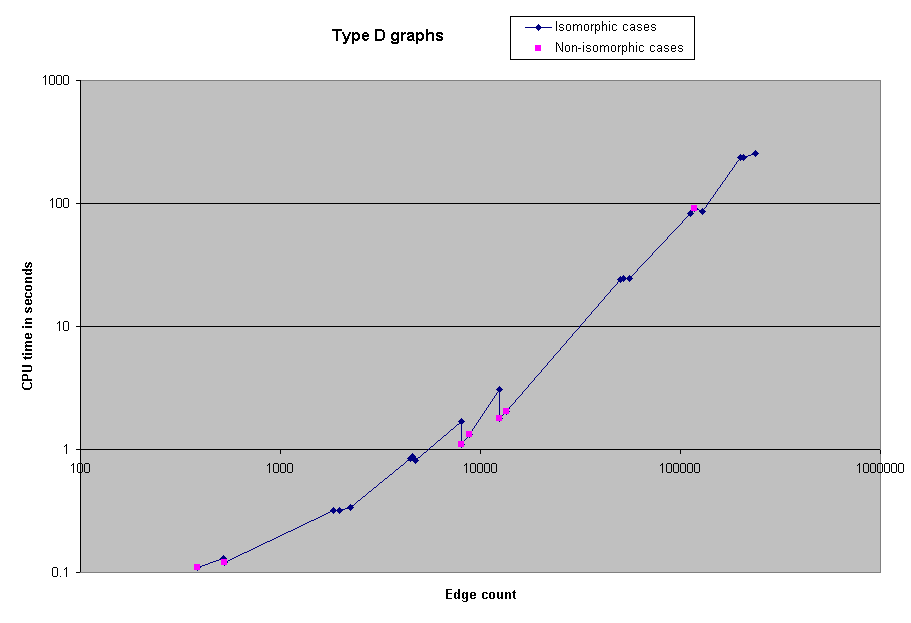
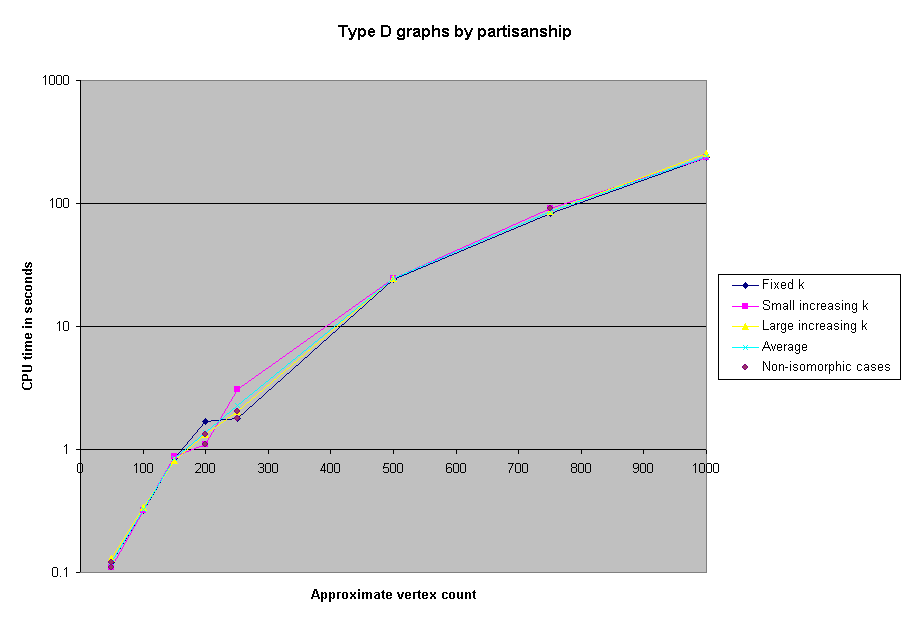
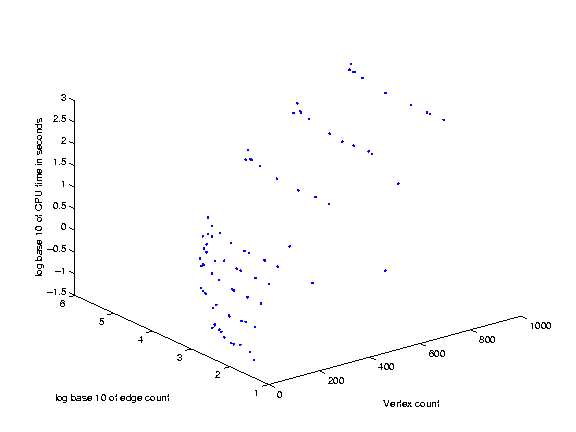
We were able to solve all the benchmark problems except two 5000-node problems. As a reference, we were able to solve the 1000 node problem in approximately 4 minutes of CPU time. However, some of the the 5000 node problems took several real-time hours.